


电 话:18962872668
网 址:www.mccn-ad.com
地 址:海门市开发区北海东路105号
2025年8月26日,元戎启行重磅发布新新一代辅佐驾驭渠道——DeepRoute IO 2.0及其中心——自研的VLA(Vision-Language-Action)视觉-言语-动作大模型。标志着辅佐驾驭技能范式的一次重要改变,从传统规矩驱动或单一感知的端到端模型,迈向了交融感知、认知与决议计划的通用AI的新阶段。
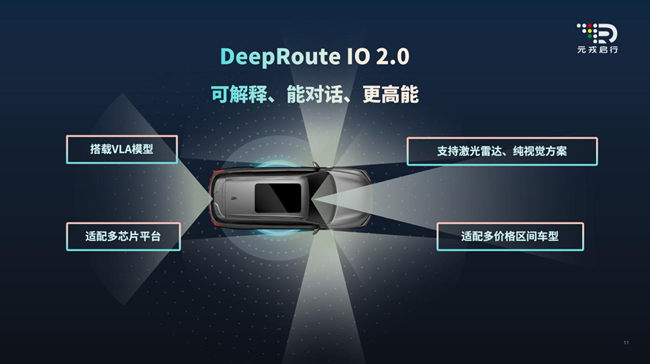
自研VLA模型是本次发布的中心打破。它将视觉感知、语义了解与动作决议计划三大才能整合于一体。与传统“黑盒”端到端模型比较,VLA模型学习了言语模型的“思想链”才能,可以像人类相同进行信息串联、剖析和因果推理,从而在面临杂乱多变的实在路况时,做出更安全、更舒适、更拟人化的决议计划。依据元戎启行CEO周光现场介绍:“其天然集成的海量知识库,也使其具有了史无前例的泛化才能。”
空间语义了解是本次发布的最大亮点。该功用可在视界受限的动态或静态盲区环境中(如公交车遮挡、杂乱路口、桥洞等)感知潜在危险,自动对盲区进行 “预防性预判”。系统可在危险呈现前提早减速、保险通行,具有高度拟人化的防御性驾驭战略,为用户所带来更安心的出行体会。
其他三项才能也各具特色:异形妨碍物辨认使系统可以辨认并灵敏应对如施工锥桶、超载小卡车等非结构化妨碍;文字类引导牌辨认让系统“看懂路标”,精确解析潮汐车道、公交专用道等文字信息;回忆语音控车功用支撑自然言语指令交互,并逐渐学习用户偏好,带来更具个性化与拟人化的驾驭体会。
在此次发布会上,元戎启行同步展现VLA模型的4大功用:空间语义了解、异形妨碍物辨认、文字类引导牌了解、回忆语音控车,这些功用将依据实践布置节奏逐渐开释。

在推动技能革新的一起,元戎启行的商业化进程相同坚实。DeepRoute IO 2.0渠道秉持“多模态+多芯片+多车型”的规划理念,兼具激光雷达与纯视觉两种计划,适配性极广。公司现在已获5个定点合作项目,并已累计交给近10万台搭载其城市领航辅佐系统的量产车,包括SUV、MPV、越野车等多个车型。也为后续VLA模型的快速、规模化、商业化落地奠定了坚实基础。
周光总结:“10万量产是一个起点。跟着高阶辅佐驾驭商场的加快翻开,咱们一直信任像元戎启行这样具有中心技能才能的公司将迎来更大的商场空间。”

元戎启行后续将环绕VLA模型继续拓宽使用鸿沟,在乘用车商场加快量产布置的一起,推动根据量产车渠道的Robotaxi事务。
在更宽广的Road AGI系统中,VLA模型也将向更多可移动智能体延展复用,逐渐实现从单点功用到通用智能体的系统化演进。


